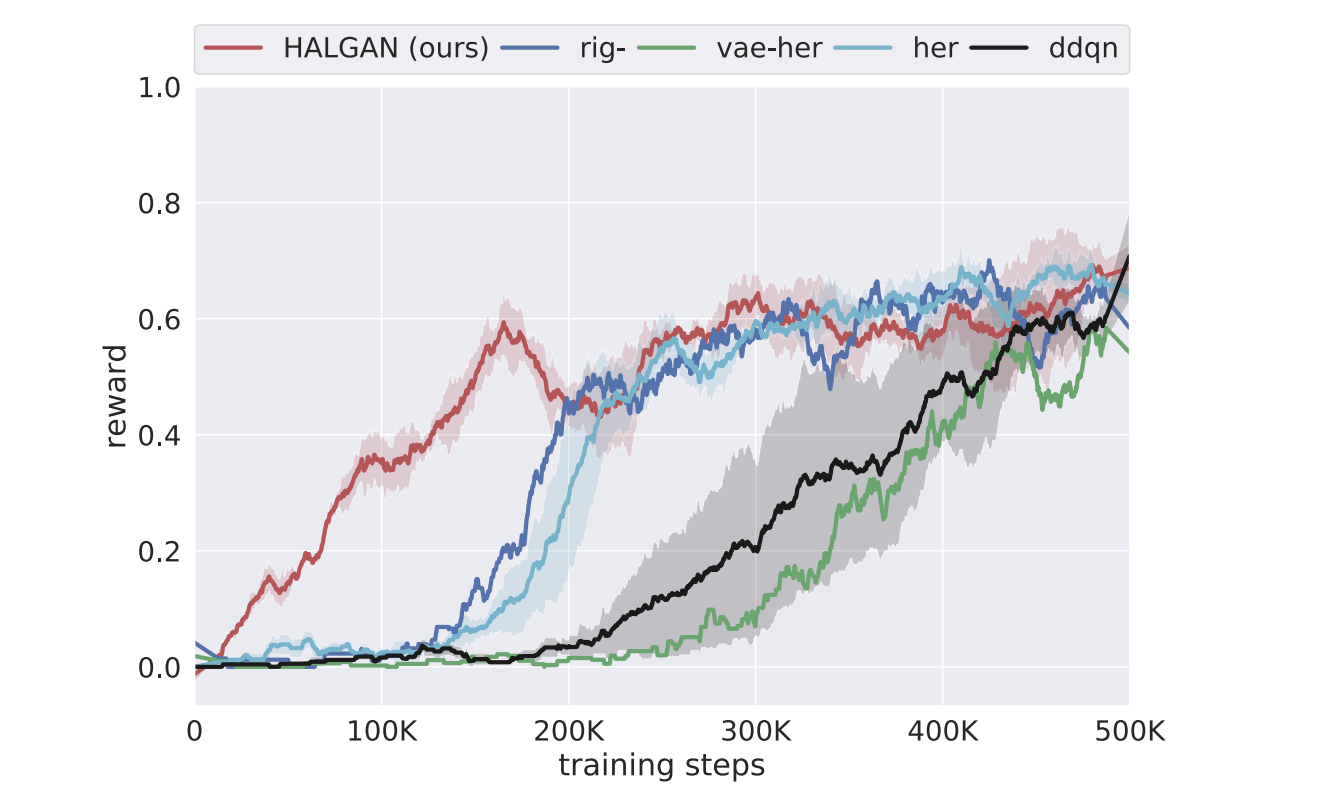
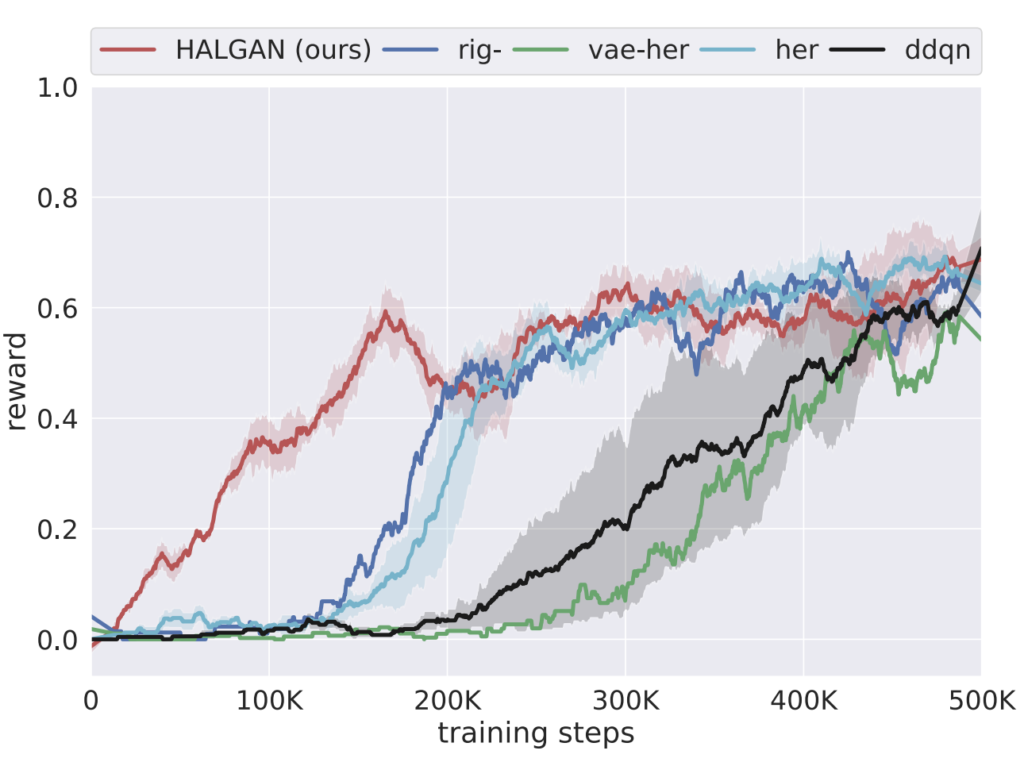
Extending HER to visual domain with GANs
Cover story for the research paper by Himanshu Sahni, Toby Buckley, Pieter Abbeel and Ilya Kuzovkin
Addressing Sample Complexity in Visual Tasks Using Hindsight Experience Replay and Hallucinatory GANs
ICML 2019 Workshop on Reinforcement Learning for Real Life
An end-to-end reinforcement learning (RL) process starts with an agent that randomly interacts with the environment, hoping to score some rewards purely by chance. Those rare occasions when the roaming agent stumbles on a reward (or on a penalty) constitute the learning experience. All other time is spent learning nothing and is wasted.
To address that obvious waste of resource a technique called Hindsight Experience Replay (HER) was introduced in 2017 by M. Andrychowicz et al. Imagine that the goal of the agent is to reach a location \(X\). But after some roaming around it ends up in location \(Y\). Usually we would discard the trajectory that led to \(Y\) and learn nothing form it. In HER, however, we pretend that \(Y\), and not \(X\), was the intended goal. This way the agent will learn what to do if, in some point in the future, its task will be to reach the location \(Y\).
At OffWorld we are trying to apply RL to real physical robots. This makes the problem of high sample complexity especially acute: all those wasted trajectories cost time, energy consumed, time spent on maintenance of a physical robot and its space parts. If in games and simulation-based RL reducing sample complexity is a nice-to-have, in robotics it often defines whether the learning will be feasible or there is no point in even attempting it. This is why we are looking at all possible sample complexity reduction techniques and implement them within our systems. HER is one of those techniques.
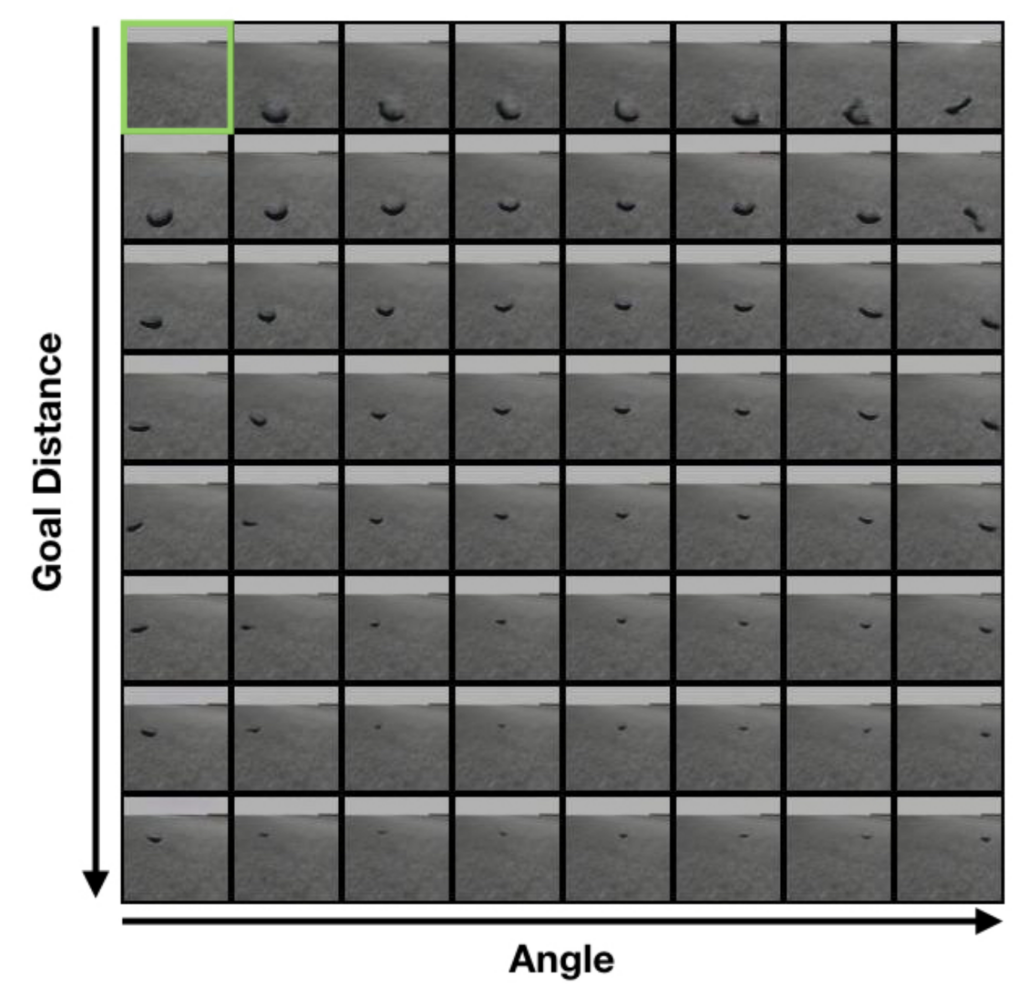
However, there is one problem with applying HER to our robots. Namely — how do we “pretend that \(Y\), and not \(X\), was the intended goal”? In original HER this was achieved by substituting the end goal configuration — just changing \((x, y)\) of the intended location does the trick. In visual domain goal state contains actual visual representation (camera frame) of the environment (Fig 1). In order to pretend that a goal was there ones has to add it to an image.


No comments yet.